MIPdatabase
MIPdatabase



Authors: Bossi AM, Sharma PS, Montana L, Zoccatelli G, Laub O, Levi R
Article Title: Fingerprint-Imprinted Polymer: Rational Selection of Peptide Epitope Templates for the Determination of Proteins by Molecularly Imprinted Polymers.
Publication date: 2012
Journal: Analytical Chemistry
Volume: 84
Issue: (9)
Page numbers: 4036-4041.
DOI: 10.1021/ac203422r
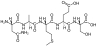
Abstract: The pool of peptides composing a protein allows for its distinctive identification in a process named fingerprint (FP) analysis. Here, the FP concept is used to develop a method for the rational preparation of molecularly imprinted polymers (MIPs) for protein recognition. The fingerprint imprinting (FIP) is based on the following: (1) the in silico cleavage of the protein sequence of interest with specific agents; (2) the screening of all the peptide sequences generated against the UniProtKB database in order to allow for the rational selection of distinctive and unique peptides (named as epitopes) of the target protein; (3) the selected epitopes are synthesized and used as templates for the molecular imprinting process. To prove the principle, NT-proBNP, a marker of the risk of cardiovascular events, was chosen as an example. The in silico analysis of the NT-proBNP sequence allowed us to individuate the peptide candidates, which were next used as templates for the preparation of NT-pro-BNP-specific FIPs and tested for their ability to bind the NT-proBNP peptides in complex samples. Results indicated an imprinting factor, IF, of ~10, a binding capacity of 0.5 - 2 mg/g, and the ability to rebind 40% of the template in a complex sample, composed of the whole digests of NT-proBNP.
Template and target information: protein, peptides, NT-proBNP



Join the Society for Molecular Imprinting
New items RSS feed
Sign-up for e-mail updates:
Choose between receiving an occasional newsletter or more frequent e-mail alerts.
Click here to go to the sign-up page.
Is your name elemental or peptidic? Enter your name and find out by clicking either of the buttons below!